数据库
Redis中的数据库是保存在一个redisServer结构中的db数组中的。db数组的每一项都是一个redisDb结构,每个结构代表着一个数据库。1
2
3
4
5
6
7
8struct redisServer{
//...
// 数组,保存着服务器中的所有数据库
redisDb *db;
// 服务器的数据库数量
int dbnum;
//...
}
dbnum属性的值未服务器 包含的数据库的数量,由服务器配置决定,默认为16个数据库。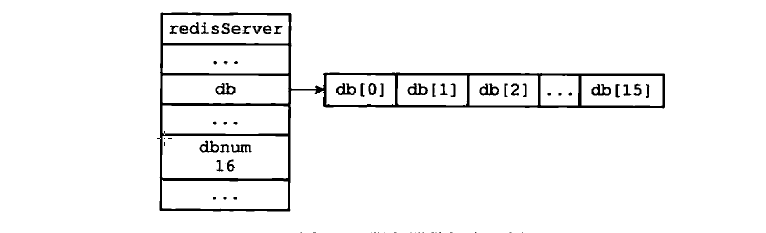
并且在服务器内部,客户端状态redisClient结构的db属性记录了当前客户端的目标数据库,这个属性是一个redisDb结构的指针,指向redisServer.db中的其中一个元素,而被指向的元素就是客户端的目标数据库。
每个数据库和其他数据库都是互不相干的。都存储着自己的数据,使用dict字典保存数据库中的所有键值对。称之为键空间。 这个键空间的键也就是数据库的键,每个键对象都是一个字符串对象。而值可以是5中基本对象类型之一。
比如下图: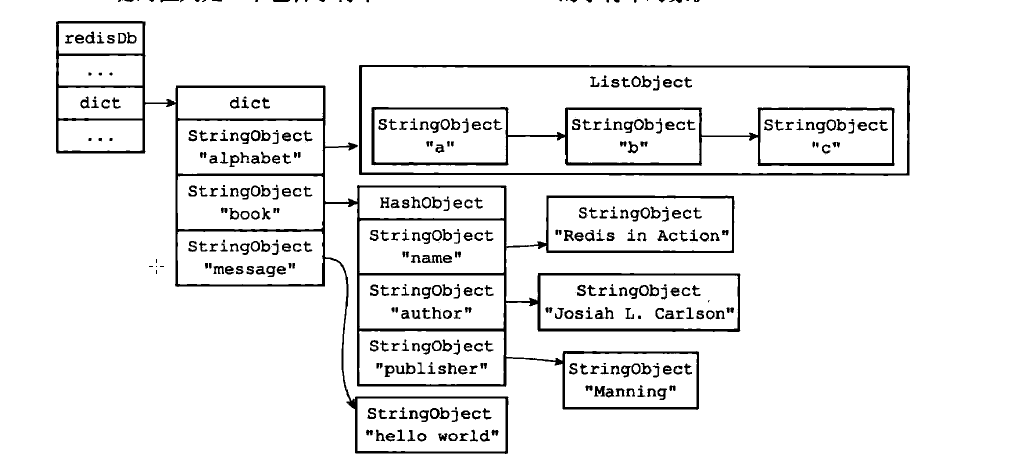
过期键
Redis支持设置键的过期时间,使用expire命令来实现。
在Redis中,过期键是保存在redisDb结构中的expires属性里的,expires也是一个字典。字典的键是指向设置有过期时间的键对象的指针,值是过期时间,用一个long long类型的整数表示–是一个毫秒精度的unix时间戳。
看下面带有过期键的redis数据结构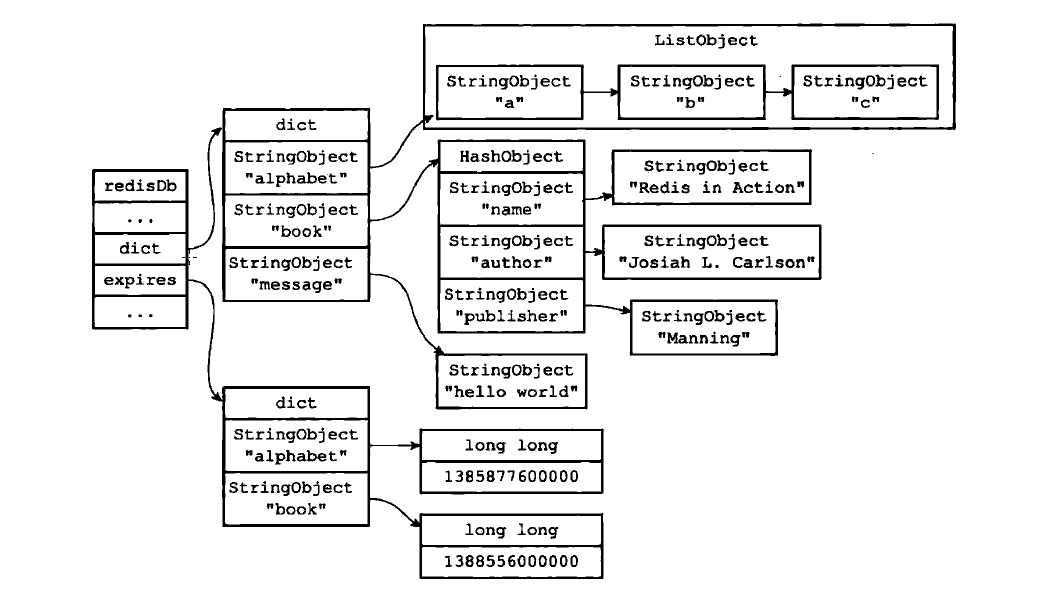
在这里,为了清楚,所以book对象和alphabet对象有两个表示,实际上在Redis中,键空间中的键和过期字典中的键都指向同一个键对象,所以不会浪费空间。
过期键删除
对于过期键删除策略:
- 定时删除: 在设置键的过期时间的同时,创建一个定时器,让定时器在过期时间来临的时候,立即执行删除操作
- 惰性删除: 放任过期键不管,但是每次从键空间获取键的时候,都检查取得的键是否过期,如果过期的话就删除该键,否则返回。
- 定期删除: 每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键,至于删除多少键以及检查多少数据库,由算法来决定。
对于这三种情况来说,
- 定时删除是对内存友好的,因为只要时间一到,过期键就会被删除,然后释放过期键占用的内存。但是这样的话会对cpu造成很大的负担,比如在cpu时间非常紧张的情况下,又有大量的过期键,这个时候用大量的时间来删除过期键显然不是一个明智的选择。 并且,创建一个定时器需要用到Redis服务器中的时间事件,而当前时间事件的实现方式—-无序链表,查找一个事件的时间复杂度为O(N),并不能高效的处理大量时间事件。 所以这种情况不好
- 惰性删除是对CPU友好的,以为程序只会在取出键的时候才对键进行过期检查,这可以保证删除过期键的操作只在非做不可的情况下才会删除。 但是这也会导致浪费内存,因为只有再取出键的时候才会删除键,因此,当有大量的过期数据并且不再需要访问了,那么就会堆积在数据库,对数据库造成一定的影响。 比如说日志,在某个时间点之后就没有用了。
- 定期删除 : 上面来看,定时删除和惰性删除都是有一定的缺陷的,而定期删除是这两种方式的一种中和。这种策略是每隔一段时间进行一次数据库的过期键删除操作,并通过限制操作执行的时长和频率来减少删除操作对CPU时间的影响。 对于定期删除,要把握好删除操作的执行时长和执行频率,否则会退化成为定是删除或者惰性删除。
Redis中删除策略的实现
在Redis中,使用惰性删除和定期删除两种方式来实现过期键删除的。
首先,Redis会在每次读写之前首先检查键是否过期,如果过期就删除,否则执行相应操作。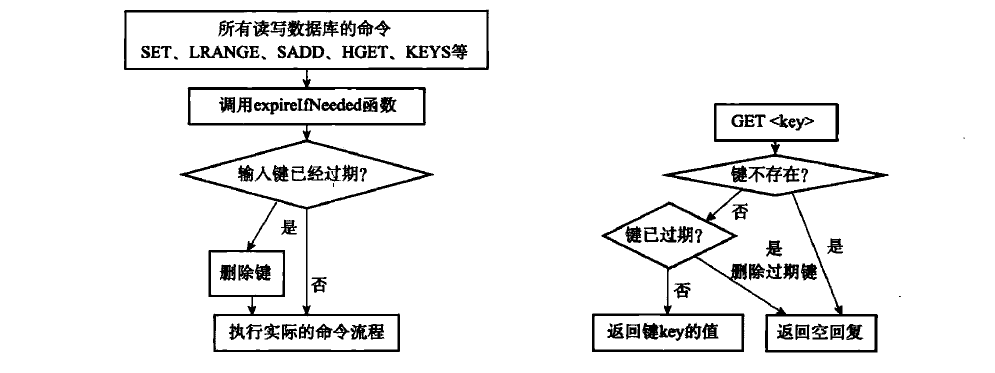
其次,Redis定义一个时间事件,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
Redis会在每次执行时间事件的时候,从一定数量的数据库中随机选取一部分键进行检查,并且删除其中的过期键。 用一个current_db来保存当前遍历到那一个数据库了。以便下一次从这里开始执行。
RDB持久化对过期键的处理
在服务器对RDB文件载入的过程中:
- 如果是主服务器,那么在载入RDB文件的时候回对键进行检查,未过期的键会被加载到数据库中,过期键会被忽略。
- 如果是从服务器,那么服务器会载入RDB文件中的所有键,而不会管是不是过期了。 因为在之后的主从同步的时候从服务器的数据库也会被清空,所以说,过期键对载入RDB文件的从服务器不影响。
AOF持久化对过期键的处理
和RDB类似,在执行AOF重写的过程中,程序会对数据库中的键进行检查,已过期的键不会被保存到重写后的AOF文件中。
复制
在复制模式下,从服务器的过期键删除由主服务器控制
- 主服务器在删除一个键之后,会显示的向所有服务器发送一个del命令,告知从服务器删除这个过期键。
- 从服务器在执行客户端发送的命令,即使碰到过期键也不管,直接向客户端返回数据。 只有收到来自主服务器发来的del命令才会删除过期键。
这样子做主要是为了保证主服务器和从服务器的数据一致性。
但是我觉得这样可能会有bug,本来应该过期的数据,我到从服务器竟然取到了,可能又bug。不好。在此我认为,应该让从服务器碰到过期键向主服务器发送一条消息。告知主服务器应该删掉这个过期键。
客户端
Redis是一对多服务器程序,一个服务器可以与多个客户端建立连接,并且每个客户端都可以发送命令请求向服务器。 服务器通过使用I/O多路复用计数来实现文件事件处理器。 并且Redis服务器使用单线程单进程的方式来处理命令请求。
在Redis服务器中,为每个连接过来的客户端保存一个称为redisClient结构的客户端状态,这个结构保存了当前客户端的状态,以及执行相关功能时需要用到的数据结构。1
2
3struct redisServer{
list *clients;
}
Redis服务器中,用一个双向链表来保存所有已连接的客户端信息。如下图所示:
下面来看一下redisClient结构中都有哪些属性 :
| 类型 | 变量名 | 含义 |
|---|---|---|
| int | fd | 描述客户端正在使用的套接字。整形,如果为-1,表示为伪客户端,来源于AOF恢复或LUA脚本。 |
| robj * | name | 名字,默认每个客户端是没有名字的,可以设置 |
| int | flag | 记录客户端处于什么角色或者说正处于什么状态 |
| sds | querybuf | 输入缓冲区,客户端发来的请求命令将保存到这里 |
| robj ** | argv | 一个数组,保存着从输入缓冲区分析出来的请求命令的参数。 命令名称也算一个参数 |
| int | argc | 整数,表示有多少个参数 |
| struct redisCommand * | cmd | 命令的实现函数,在解析完命令之后,会找到命令所对应的执行函数的redisCommand结构,然后将cmd指向此结构 |
| char* | buf | 固定长度的输出缓冲区,用来实现一些简短的命令回复, 默认大小16KB |
| int | bufpos | 记录了buf中已使用的字节数量 |
| list* | reply | 变长的输出缓冲区,当输出太大或者溢出固定的输出缓冲区,输出缓冲区会转变为一个链表结构 |
| int | authenticated | 用于记录客户端是否通过了身份验证,1为通过,0 为没通过 |
| time_t | ctime | 记录创建客户端的时间,用来计算客户端与服务器连接了多少秒 |
| time_t | lastinteraction | 记录客户端与服务器最后一次互动的时间 |
| time_t | obuf_soft_limit_reached_time | 记录输出缓冲区第一次达到软性内存限制的时间 |
创建与关闭
创建的时机就是在客户端连接服务器的时候,服务器会为客户端创建一个redisClient结构,并且存放在服务器的redisClient链表中。
关闭
- 客户端退出
- 客户端发送的命令请求不符合协议格式
- 客户端是Client Kill命令的目标
- 设置了timeout选项,并且客户端的空转时长超过了timeout选项
- 客户端发送的命令请求的大小超过了输入缓冲区的限制大小(1GB)
- 要发送给客户端的命令恢复大小超过了输出缓冲区大小
服务器
服务器在接受到客户端的命令之后,首先会解析协议,放到客户端状态的argv属性中,之后通过argv[0]参数,在命令表中查找参数所指定的命令。并将找到的命令保存到客户端状态的cmd属性里。
命令表其实是一个字典,键是一个个的命令名字,值是一个redisCommand结构,每个redisCommand结构记录一个redis命令的实现信息。如下图 :
| 属性名 | 类型 | 作用 |
|---|---|---|
| name | char * | 命令名字 ,如 “set” |
| proc | redisCommandProc * | 函数指针,执行命令的实现函数 |
| arity | int | 命令参数的个数,用于检查命令请求的格式是否正确,如果值未-N,则表示数量大于等于N ,并且,命令名称也算一个参数 |
| sflags | char * | 字符串形式的标示值,这个值记录命令的属性,比如此命令是一个写命令还是只读等等 |
| flags | int | 对sflags标识进行分析的出的二进制标识,由程序自动生成 |
| calls | long long | 服务器总共执行了多少次此命令 |
| milliseconds | long long | 服务器执行这个命令所消耗的时间 |
当有了执行命令的参数之后,服务器会在一次事件循环中,执行这个命令.执行命令的过程如下:
- 进行执行命令前检查,比如客户端状态的cmd指针是否指向NULL,参数个数是否正确,是否通过了身份验证等等
- 通过cmd指针调用命令实现函数
- 执行后续工作,比如进行AOF持久化,添加慢查询日志,将此命令传给从服务器等等.
- 将命令产生的回复发送给客户端
serverCron函数
Redis服务器中有一个serverCron函数,默认100毫秒执行一次,这个函数负责管理服务器资源,并保存服务器自身的良好运转. 下面来列一下serverCron函数都做了什么
- 更新服务器时间缓存, Redis会缓存系统当前时间,因为获取系统当前时间会调用系统调用,为了减少系统调用次数,
- 服务器状态中的unixtime属性和mstime属性被用作时间缓存, Redis会每100毫秒更新一次这两个属性. 当然,这两个不精确的时间只会用在打印日志,更新服务器的LRU时钟,计算服务器上线时间等对时间精确度要求不高的功能上.
- 更新LRU时钟. 服务器状态保存了一个lrulock的值,用来计算某个对象的空转时长. 前面知道每个对象也是有一个lru属性,计算对象的空转时长就是用这个lru时钟减去对象的lru属性获得.并且,LRU时钟默认是每10秒更新一次,因此,计算出来的空转时长是一个大概的估计值
- 更新服务器每秒执行命令次数
- 更新服务器内存峰值记录,每次serverCron函数执行时候都会检查目前服务器的内存大小,和服务器状态中的内存峰值比较,如果比记录大,则替换掉
- 处理SIGTERM信号,这个信号就是将服务器的关闭状态设置为1. 在serverCron函数中会判断是否为1,如果为1,关闭数据库
- 管理客户端资源, 在这个函数中,会对一定的客户端数量进行检查,检查与客户端的连接是否超时,缓冲区是否耗费了过多内存等等.如果有,则释放掉连接
- 管理数据库资源. 对数据库中的一部分键值对进行检查,删除掉其中的过期键
- 检查持久化操作的运行状态,用两个字段来表示是否有子进程在进行持久化,如果有,则判断子进程是否发来完成信号,如果发来,则替换掉旧的持久化文件.如果没有,则什么都不做. 如果没有子进程在进行持久化,则判断是否满足持久化的条件,如果满足,则进行持久化.
- 将AOF缓冲区的内容写入AOF文件
- 增加cronloops的次数,cronloops记录了serverCron执行的次数